Плазмена карта/редуцира малко по-бързо от Hadoop
Тест за изпълнение – от Герд Столпман, 2012-02-01
Миналата седмица прекарах известно време в работа върху карта/редуцира в Amazon EC2. По-специално, сравнявах изпълнението на Плазма, собствената си карта/редуцира, с Hadoop. Просто исках да знам до колко моето изпълнение изоставаше от най-популярната карта/редуцира рамка. Изненадата обаче беше, че плазмата се оказа малко по-бърза в тази конфигурация.
Аз не бих нарекъл този тест “бенчмарк”. Amazon EC2 не е контролирана среда, тъй като винаги получавате само частични машини и не знаете колко ресурси се консумират от други потребители на същите машини. Също така, не можете да сте сигурни доколко възлите са изключени един от друг в мрежата. И накрая, има някои специални ефекти, идващи от технологията за виртуализация, особено първият запис на дисков блок е по-бавен (приблизително половината от нормалната скорост), отколкото след писането. Въпреки това, EC2 е достатъчно добър, за да получи впечатление за скоростта и може да се надяваме, че всички проведени тестове ще получат средно един и същ недостатък.
Задачата беше да се сортират 100G данни, дадени в 10 файла. Всеки ред има 100 байта, разделени на ключ от 8 байта, TAB символ, 90 случайни байта като стойност и LF символ. Ключът е произволно избран от 65536 възможни стойности. Това означава, че има много линии със същия ключ – сценарий, където мисля, че е по-характерно за картата/разреждане, отколкото да имаш уникални ключове. Резултатът е разделен на 80 серии.
Разпределих 1 по-голям възел (m1-xlarge) с 4 виртуални ядра и 15G от RAM, действащи като комбинирани възли от имена и данни, и 9 по-малки възли (m1-големи) с 2 виртуални ядра и 7.5G RAM за другите възлови данни. Всеки възел има достъп до два виртуални диска, конфигурирани като RAID-0 масив. Скоростта за последователно четене или писане е около 160 MВ/s за масива (но само за 80 MB/s за блоковете за първи път са били написани). Очевидно възлите са имали Gigabit мрежови карти (максималната скорост на трансфер е около 119MB/s).
По време на тестовете наблюдавах системната активност със софтуера sar. Наблюдавах значителна кражба на цикъл (което означава, че виртуалното ядро е блокирано, защото няма свободно реална ядро), често достигаща стойност от 25%. Това би могло да се тълкува като претоварване на наличните ресурси, но друго обяснение е, че хипервизорът се нуждае от това време само за себе си. Във всеки случай, този ефект също поставя под въпрос надеждността на този тест.
Съпротивата
Hadoop е на върха в сцената с карта/редуцира. В този тест се използва версията от Cloudera 0.20.2-cdh3u2, която съдържа повече от 1000 пластири срещу vanilla версията 0.20.2. Написано в Java, тя се нуждае от JVM по време на изпълнение, което тук беше IcedTea 1.9.10, разпространяващо OpenJDK 1.6.0_20. Не направих никакво регулиране, надявайки се, че конфигурацията ще е добра за малката работа. Размерът на блока HDFS е 64M, без копиране.
Претендент е Плазмена карта/редуцира. Започнах този проект преди две години в свободното си време. Той не е клон на архитектурата на Хадоп, но включва много нови идеи. По-специално, много работа отиде в класифицирана файлова система PlasmaFS, която разполага с почти пълен набор от операции на файлове и управлява директно разположението на диска. Алгоритъмът на Картата/разреждане използва малко по-различна схема, която се опитва да забави разделянето на данните, за да получи по-големи междинни файлове. Плазмата се изпълнява в OCaml, който не е базиран на VM, но компилира кода директно в езика за сглобяване. При този тест блоковата разделителна способност е 1 М (плазмата е предназначена за блокове с по-малки размери). Софтуерната версия на плазмата е приблизително 0.6 (няколко версии на svn преди пускането на 0.6).
Резултати
Време на изпълнение:
| Hadoop: | 2265 секунди (37 мин, 45сек) |
| Плазма: | 1975 секунди (32 мин. 55сек) |
Предвид несигурността на околната среда, това не е голяма разлика. Но нека да разгледаме по-отблизо дейността на системата, за да получим представа защо плазмата е малко по-бърза.
Процесор
По-нататък взех само един от дейтанодите и създадох диаграми (с kSar):
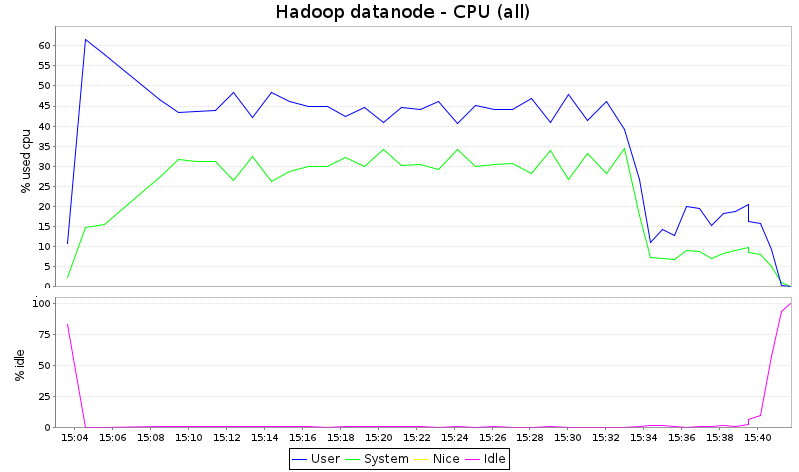
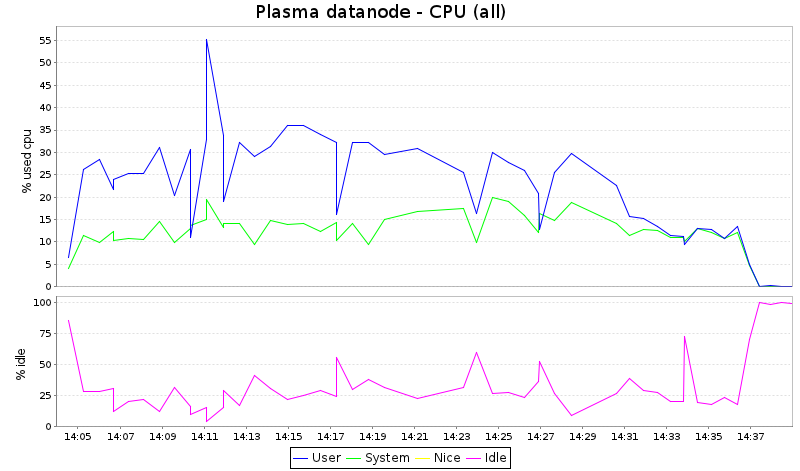
Имайте предвид, че kSar не гради графики за % iowait и % steal, въпреки че тези данни са записани от sar. Това е обяснението защо сумата от потребител, система и празен ход не е 100%.
Това, което виждаме тук, е, че Hadoop консумира всички CPU цикли, докато плазмата оставя около 1/3 от капацитета на CPU неизползвана. Предвид факта, че този вид работа обикновено е свързан с I/O-връзка, това просто означава, че Hadoop е по-гладен от процесора и би имал полза от получаването на повече ядра в този тест.
Мрежа
В тази диаграма прочитанията са синьо и червено, докато пишенето е зелено и черно. Първата крива показва пакети в секунда и вторите байтове в секунда:
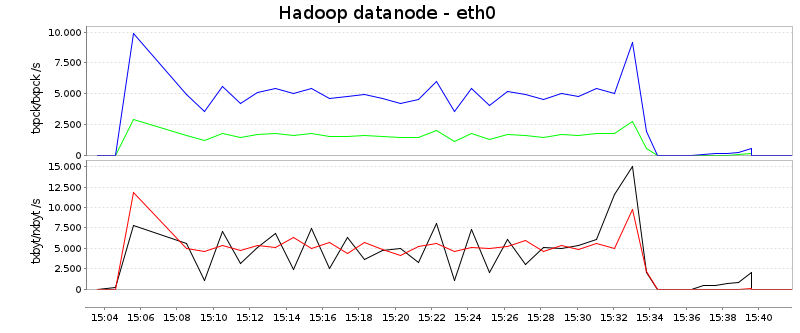
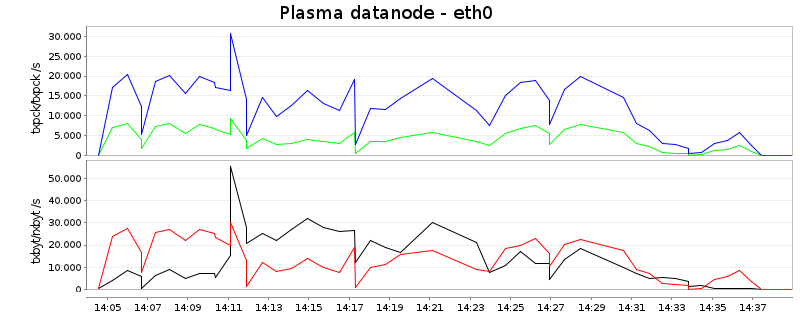
Сумирано от четене и писане, Hadoop използва средно около 7MB/s, докато плазмата предава около 25MB/s, повече от три пъти повече. Може да има две обяснения:
- Тъй като Hadoop е недостатъчно CPU, той остава под неговите възможности
- Схемата Hadoop е по-оптимизирана за поддържане на възможно най-ниската честотна лента на мрежата
Фонът за втората точка е следният: Тъй като Hadoop разделя данните непосредствено след картографиране и сортиране, данните (в идеалния случай) се използват само за преминаване през мрежата веднъж. Това е различно в плазмата, която, по принцип, разделя данните итеративно. В тази настройка след създаването и сортирането се създават само 4 дяла, които се усъвършенстват в следващите кръгове за разделяне и сливане. Тъй като тук има общо 80 дяла, има поне още една стъпка, при която разделянето на данни се усъвършенства, което означава, че данните трябва да прекосят мрежата приблизително два пъти. Това вече обяснява 2/3 от наблюдаваната разлика. (Като странична бележка, може да се конфигурира колко дялове се създават първоначално след картографиране и сортиране и би било възможно да се наподобява схемата на Hadoop, като тази стойност се зададе на 80.)
Дискове
Тези диаграми изобразяват диска чете и пише в KB / секунда:
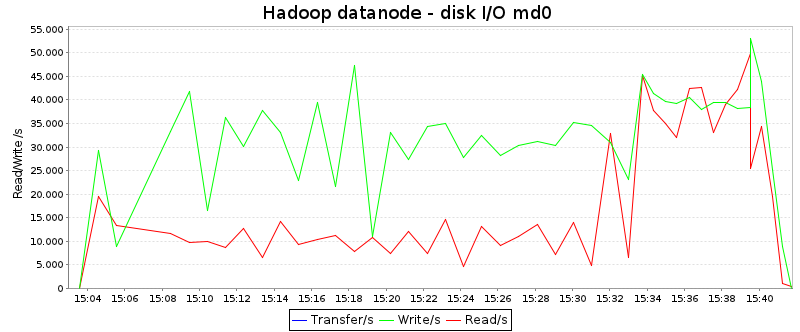
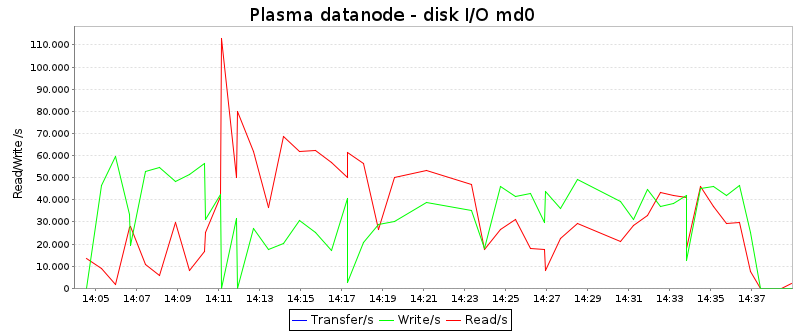
Средните стойности са (директно взети от sar):
| Hadoop | Плазма | |
| Прочетен/и: | 17,6 MB / сек | 31.2 MB / сек |
| Написан/и: | 30,8 MB / сек | 33.9 MB / сек |
Очевидно плазмата чете данни около два пъти по-често от диска от Hadoop, докато скоростта на запис е почти същата. Освен това е интересно, че формата на кривите е съвсем различна: Hadoop има период на висока дискова активност в края на работата (когато е зает с обединяване на данни), докато плазмата използва дисковете по-добре през първата трета на работното място.
Правдоподобност
Нито един от претендентите не е използвал ресурсите за I/O по всяко време. Част от трудността при разработването на схема за карта/разреждане, е да се постигне това, че натоварването върху дисковете и в мрежата да е балансирано. Не е добре, когато, например, дисковете се използват на 100% в определена точка и мрежата е недостатъчно използвана, но през следващия период мрежата е 100% и дискът не се използва напълно. Балансираното разпределение на товара достига по-висока производителност общо.
Нека анализираме плазмената схема малко по-подробно. Наборът от данни от 100G (който не се променя в обема по време на обработката), се копира общо четири пъти: веднъж във фазата на картографиране и сортиране и три пъти във фазата на намаляване (за този обем плазмата се нуждае от три сливания) , Това означава, че трябва да прехвърлим 4 * 100G данни общо или 40G данни на възел (не забравяйте, че имаме 10 възли). Направихме 22 ядра за 1975 секунди, което дава капацитет от 43450 CPU секунди. Плазмата ни казва в своите отчети, че е използвала 3822 CPU секунди за сортиране в RAM, което трябва да извадим за анализиране на пропускателната способност на I/O. На ядро това са 173 секунди. Това означава, че всеки възел е имал 1975-173 = 1802 секунди за обработка на 40G данни. Това прави около 22 MB в секунда на всеки възел.
Схемата на Hadoop се различава предимно от това, че данните се копират само два пъти във фазата на сливането (защото Hadoop по подразбиране обединява повече файлове в един кръг от плазмата). Въпреки това, поради дизайна му има допълнително копие в края на редуциращата фаза (от диск до HDFS). Това означава, че Hadoop решава една и съща работа, като прехвърля 4 * 100G данни. Няма брояч за измерване на времето, прекарано за сортиране в RAM. Да приемем, че това време е също около 3800 секунди. Това означава, че всеки възел има 2265 – 175 = 2090 секунди за обработка на 40G данни или 19 MB за секунда на всеки възел.
Заключение
Изглежда, че и двете реализации се забавят от спецификата на средата EC2. Особено дисковият вход/изход, вероятно най-важният проблем, е далеч под това, което може да се очаква.Плазмата вероятно спечели, защото използва по-ефективно CPU, докато други аспекти, като например използването на мрежата, се управляват по-добре от Hadoop.
За моя проект този резултат просто означава, че сме на прав път. Особено тази малка настройка (само 10 възли) се обработва лесно, което дава перспектива, че плазмата е мащабируема поне до малка част от това множество. Задръстването щеше да е тук, но все още има много място в главата.
Къде да получите Плазма
Plasma Map / Reduce и PlasmaFS са обединени в едно изтегляне. Ето страницата на проекта .
Герд Столпман работи като консултант на O’Caml